



Fine-tuning a Vision Transformer for Image Classification: A Beginner's Guide using Hugging Face
Using Hugging Face's ecosystem to fine tune an image classifier


Today, we're going to embark on an exciting journey into the world of computer vision using one of the coolest recent developments in AI: Vision Transformers (ViT). We'll be fine-tuning a pre-trained ViT model to classify images of cats and dogs using HuggingFace's library transformers.
The goal of this notebook is to give you an alternative to fine-tune a transformer model entirely relying on Hugging Face's ecossystem.
What's a Vision Transformer?
Before we start, let's quickly touch on what a Vision Transformer is. Traditionally, Convolutional Neural Networks (CNNs) have been the go-to for image-related tasks. However, in 2020, researchers introduced the Vision Transformer, which applies the transformer architecture (originally designed for natural language processing) to image classification tasks. And guess what? It works amazingly well!
Setting Up Our Environment
First things first, we need to set up our environment. We'll be using PyTorch and the Hugging Face Transformers library. Here's what you need to import:
from datasets import load_dataset, DatasetDict
import numpy as np
import evaluate
import torch
from transformers import AutoImageProcessor, ViTForImageClassification
from transformers import TrainingArguments, Trainer
from torchvision.transforms import (
Compose,
Normalize,
RandomHorizontalFlip,
RandomResizedCrop,
ToTensor,
)
from transformers import DefaultDataCollatorLoading and Preparing the Dataset
We'll be using the "Cats vs Dogs" dataset from Microsoft. Loading it is as easy as pie with Hugging Face's datasets library:
dataset = load_dataset("microsoft/cats_vs_dogs")Next, we'll split our dataset into training, validation, and test sets:
train_test_split = dataset["train"].train_test_split(test_size=0.1)
train_val_split = train_test_split["train"].train_test_split(test_size=0.2)
dataset = DatasetDict({
"train": train_val_split["train"],
"test": train_test_split["test"],
"validation": train_val_split["test"],
})Preparing Our Images
model_name_or_path = "google/vit-base-patch16-224-in21k"
processor = AutoImageProcessor.from_pretrained(model_name_or_path)We also need to define some image transformations. This is where the magic of data augmentation happens:
image_mean = processor.image_mean
image_std = processor.image_std
size = processor.size["height"]
normalize = Normalize(mean=image_mean, std=image_std)
_transforms = Compose(
[
RandomResizedCrop(size),
RandomHorizontalFlip(),
ToTensor(),
normalize,
]
)These transformations will randomly crop and flip our images, convert them to tensors, and normalize them. This helps our model generalize better!
model = ViTForImageClassification.from_pretrained(
model_name_or_path,
num_labels=len(labels),
id2label=id2label,
label2id=label2id,
)We're using a pre-trained model and adapting it for our specific task (classifying cats and dogs).
Training the Model
Here comes the exciting part - training our model! We'll use the Hugging Face Trainer for this:
training_args = TrainingArguments(
output_dir="./cats-vs-dogs",
learning_rate=5e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset_transformed["train"],
eval_dataset=dataset_transformed["validation"],
tokenizer=processor,
compute_metrics=compute_metrics,
)
trainer.train()This will train our model for 3 epochs, evaluating after each epoch and saving the best model.
Evaluating Our Model
results = trainer.evaluate(dataset_transformed["test"])Plot the confusion matrix.
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay, classification_report
y_true = outputs.label_ids
y_pred = outputs.predictions.argmax(1)
class_report = classification_report(y_true, y_pred)
labels = dataset_transformed["test"].features['labels'].names
cm = confusion_matrix(y_true, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
print(class_report)
disp.plot()This outputs:
precision recall f1-score support
0 0.99 0.99 0.99 1179
1 0.99 0.99 0.99 1162
accuracy 0.99 2341
macro avg 0.99 0.99 0.99 2341
weighted avg 0.99 0.99 0.99 2341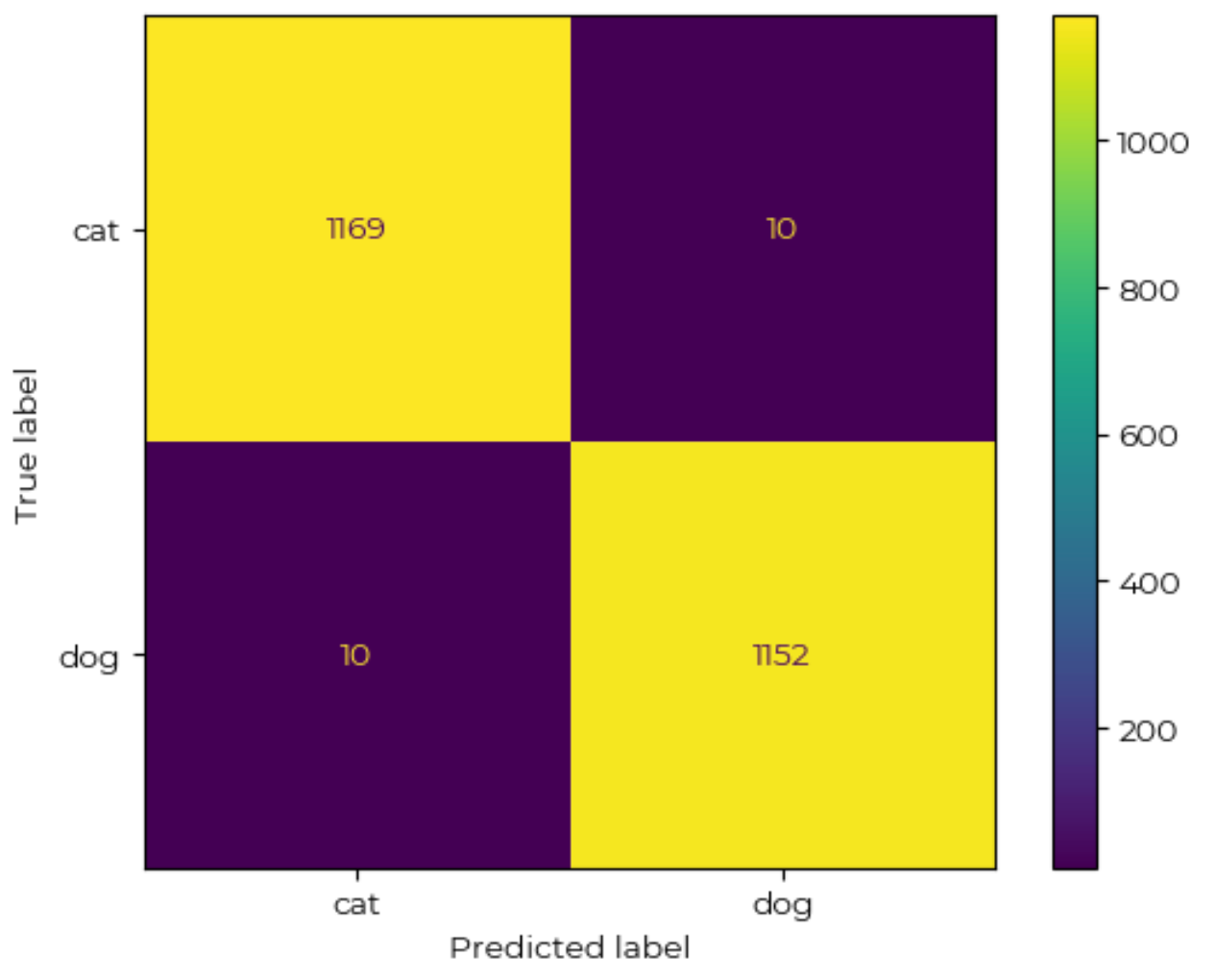
This will give us metrics like accuracy to see how well our model is performing.
Saving Our Model
Finally, let's save our trained model so we can use it later:
output_dir = "./model_output"
model.save_pretrained(output_dir)
processor.save_pretrained(output_dir)And there you have it! We've successfully fine-tuned a Vision Transformer to classify images of cats and dogs. Pretty cool, right?
Conclusion
In this blog post, we've walked through the process of fine-tuning a Vision Transformer for image classification. We've covered loading and preparing data, setting up our model, training, evaluation, and saving our model for future use.
Vision Transformers are a powerful tool in the world of computer vision, and now you have the knowledge to start using them in your own projects. Remember, the key to mastering these techniques is practice, so don't be afraid to experiment with different datasets and model configurations.
You can find this notebook here.
Happy coding, and may your models always have high accuracy!