

Fine-Tuning Large Language Models: A Beginner’s Guide
Unlock the power of LLMs: Learn when, why, and how to fine-tune your models


Large Language Models (LLMs) like GPT-3, LLaMA, or GPT-4 have shown astonishing capabilities out-of-the-box. They can generate text, answer questions, summarize information, and more — all thanks to being trained on massive text datasets. But what if you need an LLM to perform a very specific task or speak in the voice of your domain (like legal or medical)? This is where fine-tuning comes in. Fine-tuning means taking an existing pre-trained model and training it a bit more on your own data to customize its behavior. It’s a powerful way to update the model’s knowledge, adjust its style, or optimize it for a particular task
In this post, we’ll explore when you should fine-tune an LLM versus just use clever prompts (prompt engineering), what challenges fine-tuning involves, and modern techniques that make fine-tuning more efficient. We’ll demystify concepts like LoRA (Low-Rank Adaptation), quantization, QLoRA. The goal is to keep things accessible and practical – even if you’ve never worked with LLMs before, by the end you should understand the big picture and know where to start.
Prompt Engineering vs. Fine-Tuning: When Do You Need to Fine-Tune?
Prompt engineering means crafting the input prompt cleverly to get the desired output from an LLM without changing the model itself. It’s like asking the model the right way to coax a better answer. For example, instead of just saying “Summarize this,” you might say “Summarize the following text in one paragraph highlighting the key points.” A well-designed prompt can guide the model to give you what you want. The advantage of prompt engineering is that it requires no training or model changes – it’s quick to try and cost-effective. However, prompts can require a lot of trial and error, and there’s no guarantee the model will always follow them perfectly. Prompts also take up some of the model’s input length and can increase your API usage costs if you’re using a hosted model
Fine-tuning, on the other hand, actually updates the model’s parameters by training it on new data for your task. Think of a pre-trained LLM as a generalist that knows a little about everything. Fine-tuning turns it into a specialist on your task or domain. For example, if you want an LLM that excels at legal advice, you could fine-tune it on thousands of legal documents and cases. After fine-tuning, the model’s internal knowledge and behavior are directly altered to better suit that task. This means you don’t have to cram all your instructions into a prompt each time – the model intrinsically knows how to behave in the new domain.
So when do you use each approach? Here are some general guidelines:
Use Prompt Engineering when: your task can be accomplished by an existing model with the right prompt, and especially if you need a quick solution without extra training cost. Prompt tweaks are great if the base model already has the knowledge or ability you need, and you’re mainly adjusting format or style. It’s also the only option if you’re using a closed API model (like the hosted GPT-4), since you usually can’t fine-tune those directly. Prompt engineering is fast to deploy and doesn’t require special infrastructure
Use Fine-Tuning when: you need maximum performance or customization for your specific task/domain that the base model isn’t providing. If your use case requires domain-specific knowledge, a distinctive tone, or new skills the model didn’t learn in general training, fine-tuning is the way to go. Fine-tuning can significantly improve accuracy on niche tasks or incorporate proprietary data (e.g., your company’s documents) into the model’s responses. It’s worth the effort when prompt engineering still can’t get the model to consistently do what you want, or when you have to handle new types of inputs that weren’t in the model’s training data. Keep in mind fine-tuning demands more time, data, and compute resources.
There is also the otion to use Retrieval Augmented Generation (RAG) to improve the LLM's capabilities to use niche or proprietary contexts, but this is a topic for a future article.
In many real scenarios, a combination is used: you might fine-tune a model to get it roughly adapted to your task, and still use prompt engineering to steer it in specific ways. Both techniques are complementary. Prompt engineering shapes how you ask the model, while fine-tuning changes how the model actually behaves
Challenges in Fine-Tuning LLMs
If fine-tuning gives you a custom model, why not do it all the time? In practice, fine-tuning large language models comes with several challenges:
Computational Resources: Fully fine-tuning means updating all those parameters, which requires enormous memory and powerful GPUs. Training a large model from scratch or even fine-tuning it can be extraordinarily expensive and time-consuming
Data Requirements: Fine-tuning needs relevant training data. You must have a dataset of examples for the task or style you want. Collecting high-quality, domain-specific data and labeling it (if needed) can be difficult and costly.
Overfitting and Forgetting: When you train a model on your data, there’s a risk it overfits – meaning it memorizes the training examples too closely and doesn’t perform well on new inputs. Another issue is catastrophic forgetting, where the model’s new training causes it to lose some of its earlier general knowledge or capabilities.
Engineering Complexity: Fine-tuning an LLM isn’t as simple as calling an API. You need to know how to load the model in a framework like PyTorch (commonly via Hugging Face Transformers), prepare your dataset (tokenize the text, etc.), and manage the training process (setting hyperparameters like learning rate, batch size, number of epochs).
Cost and Time: Training large models with billions of parameters can take hours to days (or more) even on high-end hardware. This is a stark contrast to prompt engineering, which is instantaneous.
Model Access and Licensing: Not every model is available to fine-tune. Proprietary models (like OpenAI’s GPT-4 or Anthropic’s Claude) may not allow you to retrain them at all. Additionally, some open models have licenses that restrict commercial use or require certain attributions, so you must navigate those when fine-tuning and deploying.
The good news is that researchers have developed new techniques to make fine-tuning more efficient, mitigating some of the resource and time issues. Next, we’ll discuss a couple of these key techniques: LoRA and quantization (and a combination of both called QLoRA).
LoRA: A Lightweight Way to Fine-Tune LLMs
One breakthrough that has made fine-tuning large models easier is LoRA (paper), which stands for Low-Rank Adaptation. The core idea of LoRA is simple: don’t touch the original model weights; instead, learn a few small new weight matrices that can be added to the model’s layers to adapt it to your task. In other words, LoRA adds lightweight pieces to the original model rather than changing the entire model.
Here’s a conceptual way to think about it: Imagine your pre-trained LLM is a complex machine with millions of settings (parameters) dialed in just right. Fine-tuning by traditional methods would mean adjusting all those dials – very expensive and slow. LoRA says, “Leave those dials as they are. We’ll attach a small add-on device with just a few knobs of its own. By tuning those few knobs, we can achieve a similar effect as re-tuning the whole machine.” Concretely, LoRA inserts small low-rank matrices into the model’s layers (for example, inside the attention mechanism) which are trained to capture the adjustments needed for the new task. The original model’s weights stay frozen (unchanged), and only the small LoRA matrices get updated during training
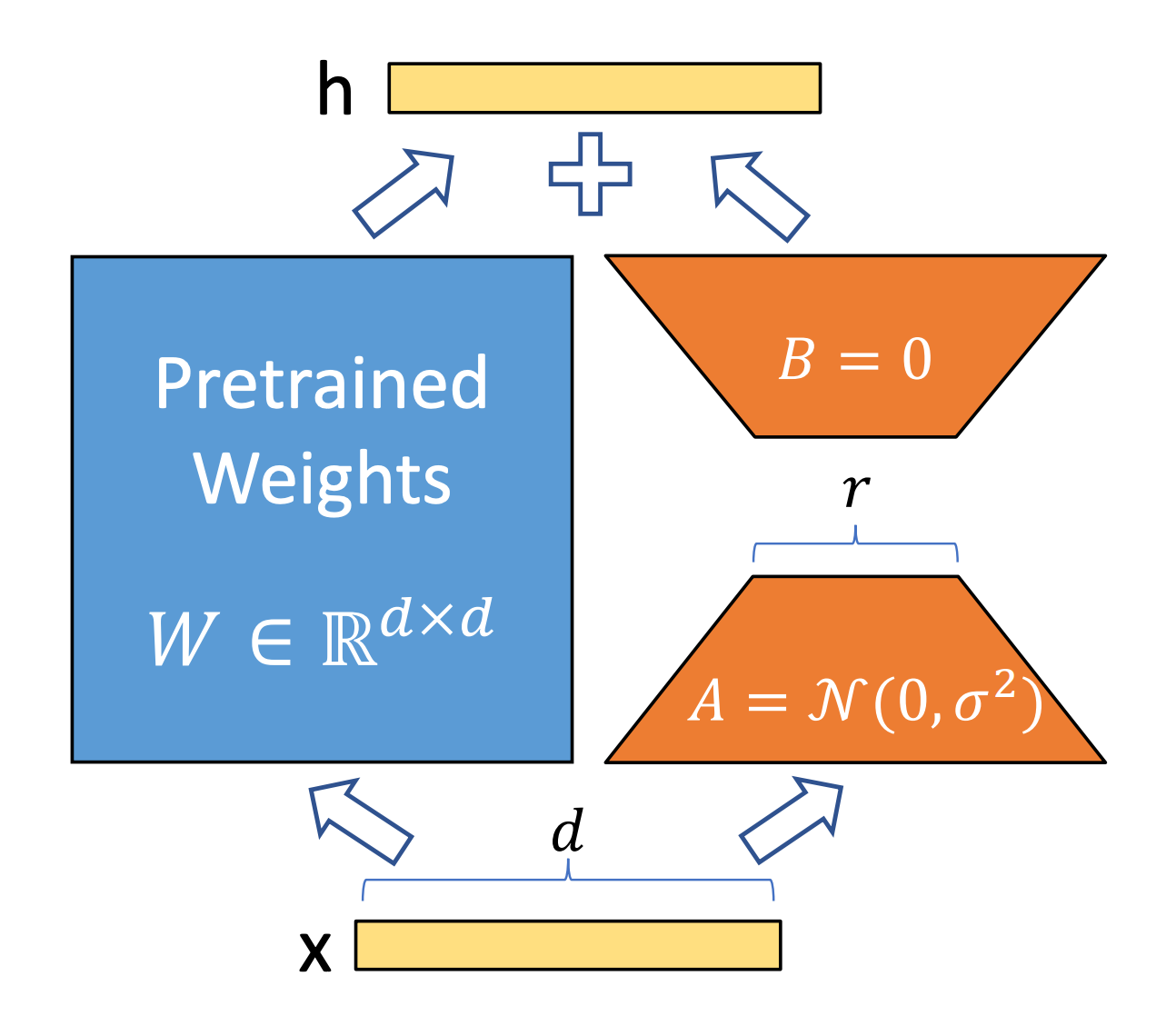
This approach has several advantages. First, the number of trainable parameters is drastically reduced – often by orders of magnitude. Second, because the original weights are intact, you can maintain multiple small LoRA “adapters” for different tasks without having to keep multiple copies of the full model, Each LoRA adapter is like a plugin that specializes the model for one task, and these adapters are usually very lightweight files. Third, when done, you can even merge the LoRA weights back into the base model for inference, so you don’t add any slowdown when using the model to generate text.
Model Quantization: Making LLMs Smaller and Faster (with Some Tradeoffs)
The next concept to understand is quantization. Quantization in the context of machine learning models means representing the model’s numbers with fewer bits, which essentially compresses the model. If you’ve heard of a model using “8-bit” or “4-bit” precision, that’s quantization. Normally, models use 16-bit or 32-bit floating-point numbers to represent all the weights (parameters) and computations. That high precision is great for accuracy, but it consumes a lot of memory. Quantization reduces the precision — for example, turning a 32-bit float weight into an 8-bit integer — which cuts down memory usage and can also speed up computation.
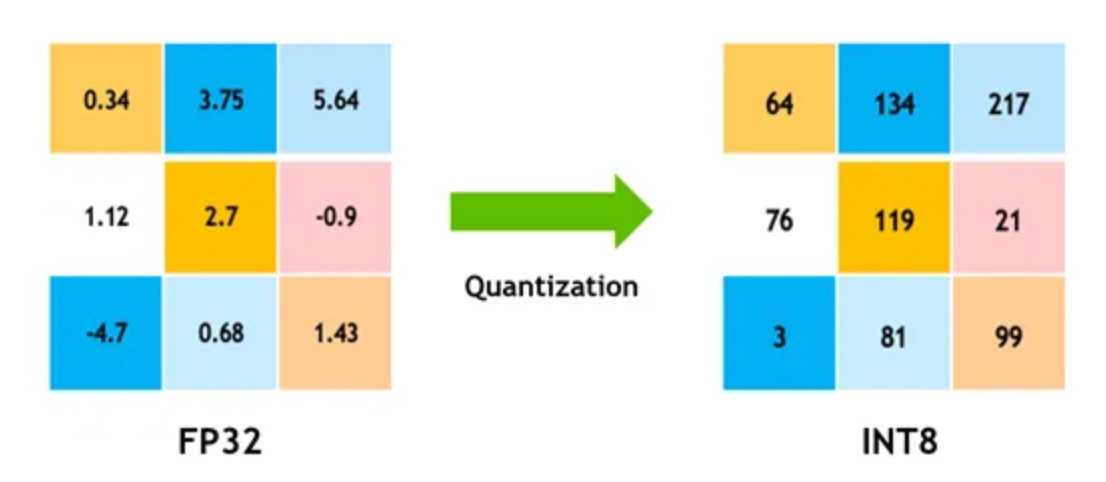
The downside is that lowering precision can affect the model’s accuracy. With fewer bits, you’re approximating the weights and you lose some detail. However, research has found ways to minimize this impact. Techniques like using a special 4-bit datatype (e.g., NF4 – Normal Float 4 used in recent papers) preserve as much information as possible, and quantization-aware training can adjust for the lost precision. The key point: quantization is usually used to make inference (using the model) cheaper and faster, not necessarily for training. In fact, training a model that’s been quantized can be unstable, because the math is less precise.
QLoRA: Fine-Tuning with Quantization + LoRA
QLoRA (Quantized LoRA - paper) is an approach that combines the two ideas above — quantization and LoRA — to reap the benefits of both. The concept was introduced in 2023 and immediately made waves because it enabled something previously impractical: fine-tuning extremely large models on a single GPU. The creators of QLoRA showed that you could fine-tune a 65-billion-parameter model on one 48 GB GPU by using 4-bit quantization on the model weights and applying LoRA on top.
How does QLoRA work? Essentially, you load the base model in a low-precision (e.g. 4-bit) mode to save memory, but you still train a LoRA adapter with higher precision gradients. The base model’s weights remain frozen (just as in regular LoRA), and they’re 4-bit numbers now. Gradients (the signals used to adjust parameters during training) are backpropagated through this quantized model into the LoRA adapters. Since only the LoRA adapter’s parameters are being updated (which are relatively few and can be kept in higher precision like 16-bit), the training remains stable and accurate, even though the base is low-precision.
The takeaway: QLoRA makes fine-tuning large models much more accessible by radically reducing memory usage while preserving accuracy. One can start with, say, a 7B or 13B parameter model and fine-tune it on a single modern consumer GPU (like an NVIDIA 3090 or 4090 with 24 GB VRAM) using QLoRA, whereas before even a 13B model might have needed 2 GPUs or 64+ GB of memory to fine-tune in full precision.
Conclusion
Stepping into the world of LLMs can be overwhelming, but understanding fine-tuning opens up a whole new level of possibilities. To recap, prompt engineering is often your first resort to get an AI model to do what you want – it’s quick and requires no model changes. But when prompts fall short or you need something truly custom, fine-tuning lets you take a pre-trained model and train it further on your own data, so it learns your task. Thanks to methods like LoRA, you don’t have to update every parameter of the model – you can add small trainable components and achieve similar outcomes with far less resources. Quantization helps by shrinking model size (using fewer bits to represent weights), and when combined in QLoRA, you get a remarkably efficient recipe to fine-tune even the largest models on common hardware.